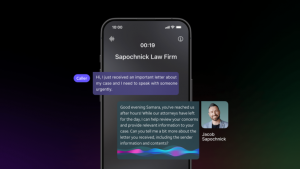
When interacting with transformer-based models like large language models (LLMs) and vision-language models (VLMs), the structure of the input shapes the…
When interacting with transformer-based models like large language models (LLMs) and vision-language models (VLMs), the structure of the input shapes the…