

Today, tweaking your PC to suit your workflows often involves digging through menus and settings across multiple control panels. Project G-Assist is an... Today, tweaking...





Isaac Sim and Isaac Lab Are Now Available for Early Developer Preview
NVIDIA today released developer previews of NVIDIA Isaac Sim and NVIDIA Isaac Lab — reference robotics simulation and learning frameworks. Now available on... NVIDIA today...

Enhance Robot Learning with Synthetic Trajectory Data Generated by World Foundation Models
Generalist robotics have arrived, powered by advances in mechatronics and robot AI foundation models. But a key bottleneck remains: robots need vast training... Generalist robotics...

AI Aims to Bring Order to the Law
A team of Stanford University researchers has developed an LLM system to cut through bureaucratic red tape. The LLM—dubbed the System for Statutory Research,... A...
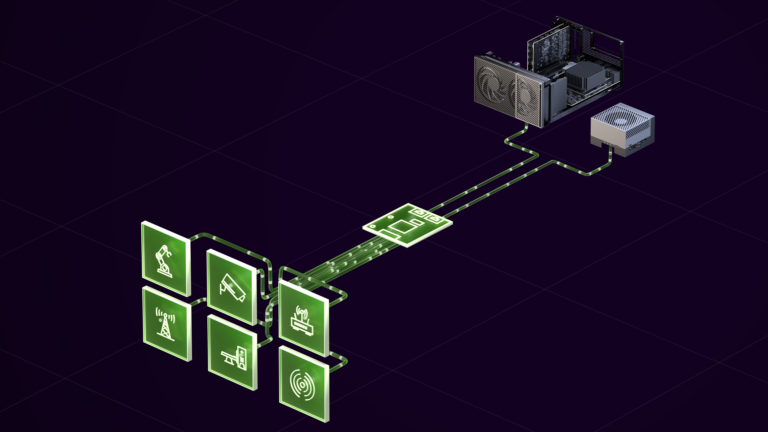
NVIDIA Holoscan Sensor Bridge Empowers Developers with Real-Time Data Processing
In the rapidly evolving robotics and edge AI landscape, the ability to efficiently process and transfer sensor data is crucial. Many edge applications are... In...