
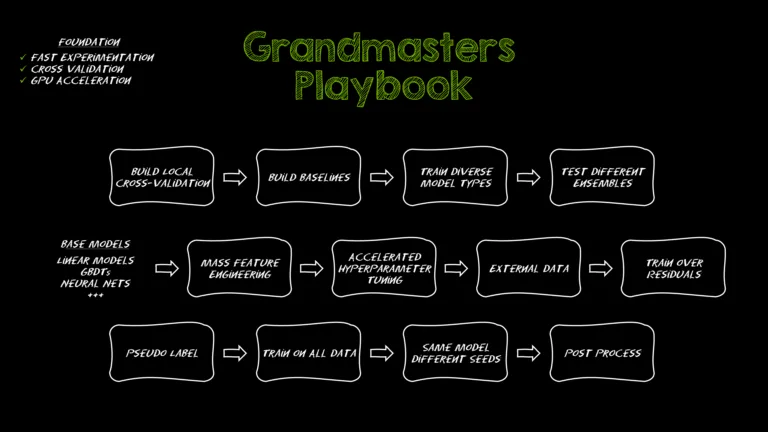
Over hundreds of Kaggle competitions, we've refined a playbook that consistently lands us near the top of the leaderboard—no matter if we’re working with... Over...




How to Reduce KV Cache Bottlenecks with NVIDIA Dynamo
As AI models grow larger and more sophisticated, inference, the process by which a model generates responses, is becoming a major challenge. Large language... As...

NVIDIA RAPIDS 25.08 Adds New Profiler for cuML, Updates to the Polars GPU Engine, Additional Algorithm Support, and More
The 25.08 release of RAPIDS continues to push the boundaries toward making accelerated data science more accessible and scalable with the addition of several... The...

An Introduction to Speculative Decoding for Reducing Latency in AI Inference
Generating text with large language models (LLMs) often involves running into a fundamental bottleneck. GPUs offer massive compute, yet much of that power sits... Generating...

Greyhawkery Comics: Saga of Valkaun Dain #16
Welcome back readers! The Saga continues, if you are new to this series check out the links below. Today is a slice of Valkaun life...