

Computer-Aided Engineering (CAE) is shifting from human-driven workflows toward AI-driven ones, including physics foundation models that generalize across... Computer-Aided Engineering (CAE) is shifting from human-driven...





Build Next-Gen Physical AI with Edge‑First LLMs for Autonomous Vehicles and Robotics
Physical AI is rapidly evolving, from next-generation software-defined autonomous vehicles (AVs) to humanoid robots. The challenge is no longer how to run a... Physical AI...
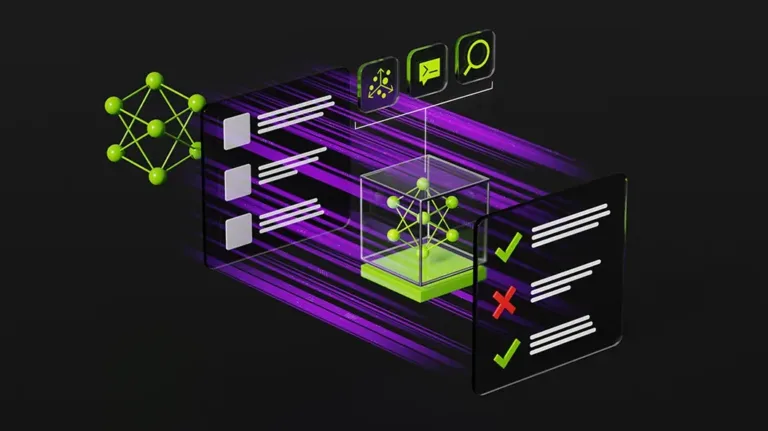
Validate Kubernetes for GPU Infrastructure with Layered, Reproducible Recipes
Every AI cluster running on Kubernetes requires a full software stack that works together, from low-level driver and kernel settings to high-level operator and... Every...

Greyhawkery Comics: Cultists #31
Welcome again to a new installment of the Cultists of Tharizdun as they make their way into the famous Steading of the Hill Giant Chief. One...

Greyhawkery Comics: Under #31
Welcome again adventurers! Last time on my short story, Under, the minions of Sallara the drow were beaten by the heroic allies of Vaelindra the...