

Large language models (LLM) are getting larger, increasing the amount of compute required to process inference requests. To meet real-time latency requirements... Large language models...




RAPIDS cuDF Unified Memory Accelerates pandas up to 30x on Large Datasets
NVIDIA has released RAPIDS cuDF unified memory and text data processing features that help data scientists continue to use pandas when working with larger and......
Improving GPU Performance by Reducing Instruction Cache Misses
GPUs are specially designed to crunch through massive amounts of data at high speed. They have a large amount of compute resources, called streaming... GPUs...
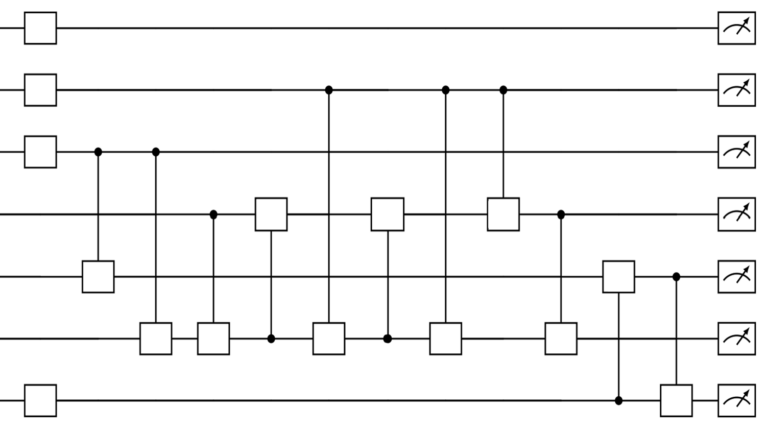
Performant Quantum Programming Even Easier with NVIDIA CUDA-Q v0.8
NVIDIA CUDA-Q (formerly NVIDIA CUDA Quantum) is an open-source programming model for building hybrid-quantum classical applications that take full advantage of... NVIDIA CUDA-Q (formerly NVIDIA...

Optimizing llama.cpp AI Inference with CUDA Graphs
The open-source llama.cpp code base was originally released in 2023 as a lightweight but efficient framework for performing inference on Meta Llama models.... The open-source...