

NVIDIA has achieved a world-record large language model (LLM) inference speed. A single NVIDIA DGX B200 node with eight NVIDIA Blackwell GPUs can achieve over......




Spotlight: Infleqtion Optimizes Portfolios Using Q-CHOP and NVIDIA CUDA-Q Dynamics
Computing is an essential tool for the modern financial services industry. Profits are won and lost based on the speed and accuracy of algorithms guiding......
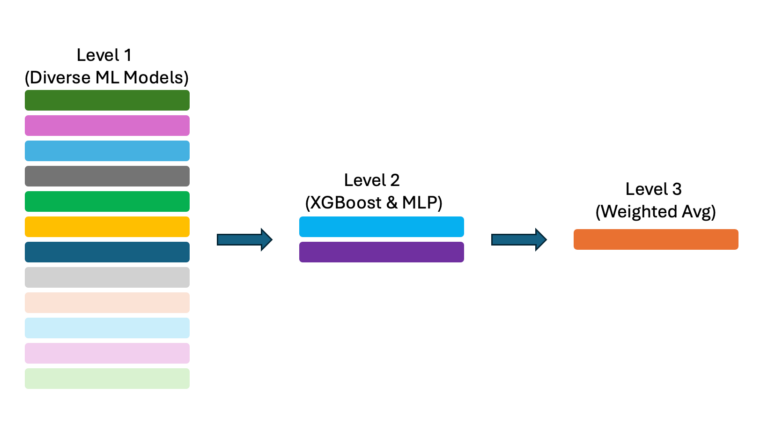
Grandmaster Pro Tip: Winning First Place in a Kaggle Competition with Stacking Using cuML
What does it take to win a Kaggle competition in 2025? In the April Playground challenge, the goal was to predict how long users would...

Greyhawkery Comics: Tasha’s Cauldron #12
Greetings Greyfolk! It's time for a new episode of Tasha. She is always cooking something up as you know. If not, check out her previous...

NVIDIA Dynamo Accelerates llm-d Community Initiatives for Advancing Large-Scale Distributed Inference
The introduction of the llm-d community at Red Hat Summit 2025 marks a significant step forward in accelerating generative AI inference innovation for the open......