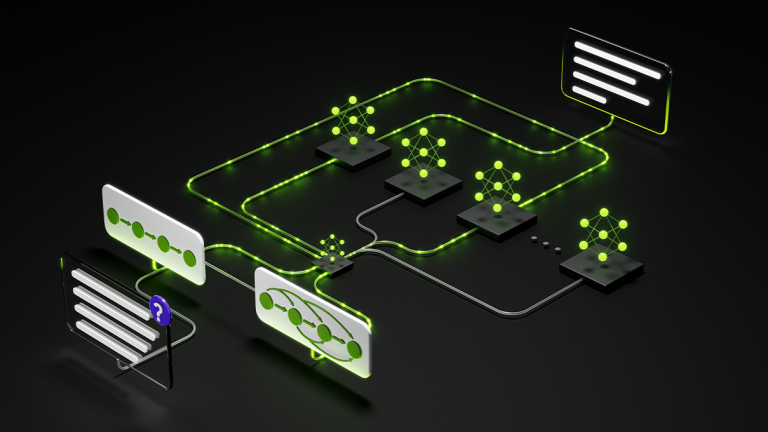
Agentic systems often reason across screens, documents, audio, video, and text within a single perception‑to‑action loop. However, they still rely on…
Agentic systems often reason across screens, documents, audio, video, and text within a single perception‑to‑action loop. However, they still rely on fragmented model chains—separate stacks for vision, audio, and text. This increases inference hops and orchestration complexity, driving up inference costs while weakening cross-modal context consistency. NVIDIA Nemotron 3 Nano Omni…