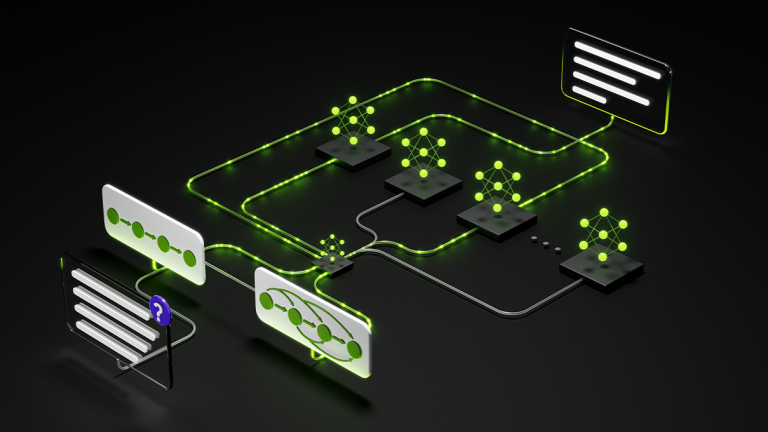
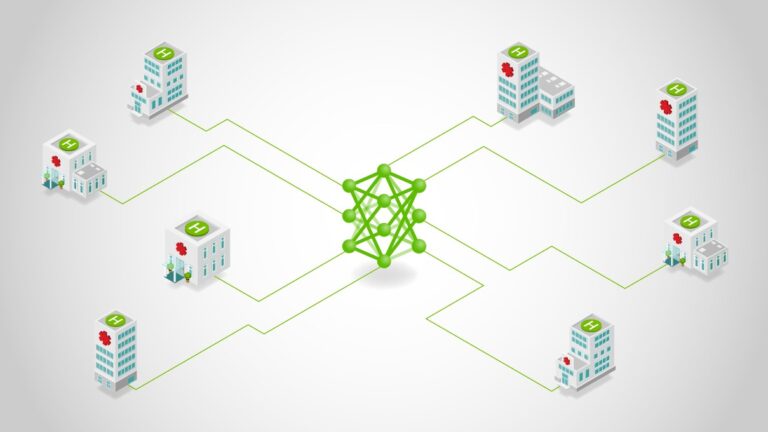
Fine-tuning and reinforcement learning (RL) for large language models (LLMs) require advanced expertise and complex workflows, making them out of reach for…
Fine-tuning and reinforcement learning (RL) for large language models (LLMs) require advanced expertise and complex workflows, making them out of reach for many. The open source Unsloth project changes that by streamlining the process, making it easier for individuals and small teams to explore LLM customization. When paired with the efficiency and throughput of the NVIDIA Blackwell GPUs…