
Modern workflows showcase the endless possibilities of generative and agentic AI on PCs.
Of many, some examples include tuning a chatbot to handle product-support questions or building a personal assistant for managing one’s schedule. A challenge remains, however, in getting a small language model to respond consistently with high accuracy for specialized agentic tasks.
That’s where fine-tuning comes in.
Unsloth, one of the world’s most widely used open-source frameworks for fine-tuning LLMs, provides an approachable way to customize models. It’s optimized for efficient, low-memory training on NVIDIA GPUs — from GeForce RTX desktops and laptops to RTX PRO workstations and DGX Spark, the world’s smallest AI supercomputer.
Another powerful starting point for fine-tuning is the just-announced NVIDIA Nemotron 3 family of open models, data and libraries. Nemotron 3 introduces the most efficient family of open models, ideal for agentic AI fine-tuning.
Teaching AI New Tricks
Fine-tuning is like giving an AI model a focused training session. With examples tied to a specific topic or workflow, the model improves its accuracy by learning new patterns and adapting to the task at hand.
Choosing a fine-tuning method for a model depends on how much of the original model the developer wants to adjust. Based on their goals, developers can use one of three main fine-tuning methods:
Parameter-efficient fine-tuning (such as LoRA or QLoRA):
How it works: Updates only a small portion of the model for faster, lower-cost training. It’s a smarter and efficient way to enhance a model without altering it drastically.
Target use case: Useful across nearly all scenarios where full fine-tuning would traditionally be applied — including adding domain knowledge, improving coding accuracy, adapting the model for legal or scientific tasks, refining reasoning, or aligning tone and behavior.
Requirements: Small- to medium-sized dataset (100-1,000 prompt-sample pairs).
Full fine-tuning:
How it works: Updates all of the model’s parameters — useful for teaching the model to follow specific formats or styles.
Target use case: Advanced use cases, such as building AI agents and chatbots that must provide assistance about a specific topic, stay within a certain set of guardrails and respond in a particular manner.
Requirements: Large dataset (1,000+ prompt-sample pairs).
Reinforcement learning:
How it works: Adjusts the behavior of the model using feedback or preference signals. The model learns by interacting with its environment and uses the feedback to improve itself over time. This is a complex, advanced technique that interweaves training and inference — and can be used in tandem with parameter-efficient fine-tuning and full fine-tuning techniques. See Unsloth’s Reinforcement Learning Guide for details.
Target use case: Improving the accuracy of a model in a particular domain — such as law or medicine — or building autonomous agents that can orchestrate actions on a user’s behalf.
Requirements: A process that contains an action model, a reward model and an environment for the model to learn from.
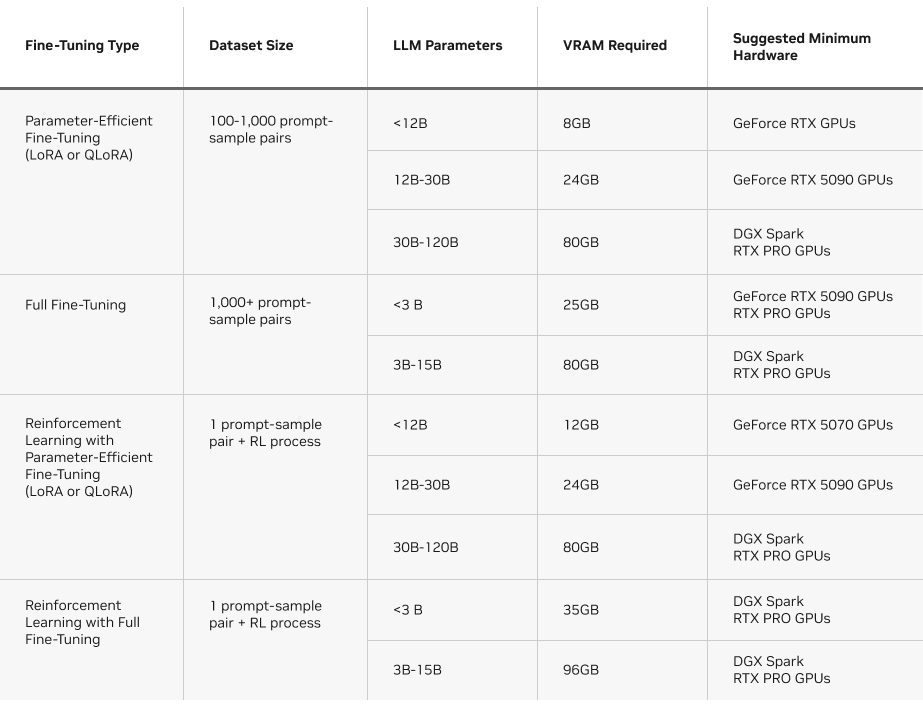
Another factor to consider is the VRAM required per each method. The chart below provides an overview of the requirements to run each type of fine-tuning method on Unsloth.
Fine-tuning requirements on Unsloth.
Unsloth: A Fast Path to Fine-Tuning on NVIDIA GPUs
LLM fine-tuning is a memory- and compute-intensive workload that involves billions of matrix multiplications to update model weights at every training step. This type of heavy parallel workload requires the power of NVIDIA GPUs to complete the process quickly and efficiently.
Unsloth shines at this workload, translating complex mathematical operations into efficient, custom GPU kernels to accelerate AI training.
Unsloth helps boost the performance of the Hugging Face transformers library by 2.5x on NVIDIA GPUs. These GPU-specific optimizations, combined with Unsloth’s ease of use, make fine-tuning accessible to a broader community of AI enthusiasts and developers.
The framework is built and optimized for NVIDIA hardware — from GeForce RTX laptops to RTX PRO workstations and DGX Spark — providing peak performance while reducing VRAM consumption.
Unsloth provides helpful guides on how to get started and manage different LLM configurations, hyperparameters and options, along with example notebooks and step-by-step workflows.
Check out some of these Unsloth guides:
Fine-Tuning LLMs With NVIDIA RTX 50 Series GPUs and Unsloth
Fine-Tuning LLMs With NVIDIA DGX Spark and Unsloth
Learn how to install Unsloth on NVIDIA DGX Spark. Read the NVIDIA technical blog for a deep dive of fine-tuning and reinforcement learning on the NVIDIA Blackwell platform.
For a hands-on local fine-tuning walkthrough, watch Matthew Berman showing reinforcement learning running on a NVIDIA GeForce RTX 5090 using Unsloth in the video below.
Available Now: NVIDIA Nemotron 3 Family of Open Models
The new Nemotron 3 family of open models — in Nano, Super, and Ultra sizes — built on a new hybrid latent Mixture-of-Experts (MoE) architecture, introduces the most efficient family of open models with leading accuracy, ideal for building agentic AI applications.
Nemotron 3 Nano 30B-A3B, available now, is the most compute-efficient model in the lineup. It’s optimized for tasks such as software debugging, content summarization, AI assistant workflows and information retrieval at low inference costs. Its hybrid MoE design delivers:
Up to 60% fewer reasoning tokens, significantly reducing inference cost.
A 1 million-token context window, allowing the model to retain far more information for long, multistep tasks.
Nemotron 3 Super is a high-accuracy reasoning model for multi-agent applications, while Nemotron 3 Ultra is for complex AI applications. Both are expected to be available in the first half of 2026.
NVIDIA also released today an open collection of training datasets and state-of-the-art reinforcement learning libraries. Nemotron 3 Nano fine-tuning is available on Unsloth.
Download Nemotron 3 Nano now from Hugging Face, or experiment with it through Llama.cpp and LM Studio.
DGX Spark: A Compact AI Powerhouse
DGX Spark enables local fine-tuning and brings incredible AI performance in a compact, desktop supercomputer, giving developers access to more memory than a typical PC.
Built on the NVIDIA Grace Blackwell architecture, DGX Spark delivers up to a petaflop of FP4 AI performance and includes 128GB of unified CPU-GPU memory, giving developers enough headroom to run larger models, longer context windows and more demanding training workloads locally.
For fine-tuning, DGX Spark enables:
Larger model sizes. Models with more than 30 billion parameters often exceed the VRAM capacity of consumer GPUs but fit comfortably within DGX Spark’s unified memory.
More advanced techniques. Full fine-tuning and reinforcement-learning-based workflows — which demand more memory and higher throughput — run significantly faster on DGX Spark.
Local control without cloud queues. Developers can run compute-heavy tasks locally instead of waiting for cloud instances or managing multiple environments.
DGX Spark’s strengths go beyond LLMs. High-resolution diffusion models, for example, often require more memory than a typical desktop can provide. With FP4 support and large unified memory, DGX Spark can generate 1,000 images in just a few seconds and sustain higher throughput for creative or multimodal pipelines.
The table below shows performance for fine-tuning the Llama family of models on DGX Spark.
Performance for fine-tuning Llama family of models on DGX Spark.
As fine-tuning workflows advance, the new Nemotron 3 family of open models offer scalable reasoning and long-context performance optimized for RTX systems and DGX Spark.
Learn more about how DGX Spark enables intensive AI tasks.
#ICYMI — The Latest Advancements in NVIDIA RTX AI PCs
FLUX.2 Image-Generation Models Now Released, Optimized for NVIDIA RTX GPUs
The new models from Black Forest Labs are available in FP8 quantizations that reduce VRAM and increase performance by 40%.
Nexa.ai Expands Local AI on RTX PCs With Hyperlink for Agentic Search
The new on-device search agent delivers 3x faster retrieval-augmented generation indexing and 2x faster LLM inference, indexing a dense 1GB folder from about 15 minutes to just four to five minutes. Plus, DeepSeek OCR now runs locally in GGUF via NexaSDK, offering plug-and-play parsing of charts, formulas and multilingual PDFs on RTX GPUs.
Mistral AI Unveils New Model Family Optimized for NVIDIA GPUs
The new Mistral 3 models are optimized from cloud to edge and available for fast, local experimentation through Ollama and Llama.cpp.
Blender 5.0 Lands With HDR Color and Major Performance Gains
The release adds ACES 2.0 wide-gamut/HDR color, NVIDIA DLSS for up to 5x faster hair and fur rendering, better handling of massive geometry, and motion blur for Grease Pencil.
Plug in to NVIDIA AI PC on Facebook, Instagram, TikTok and X — and stay informed by subscribing to the RTX AI PC newsletter. Follow NVIDIA Workstation on LinkedIn and X.
See notice regarding software product information.









{kind=link}
{kind=link}