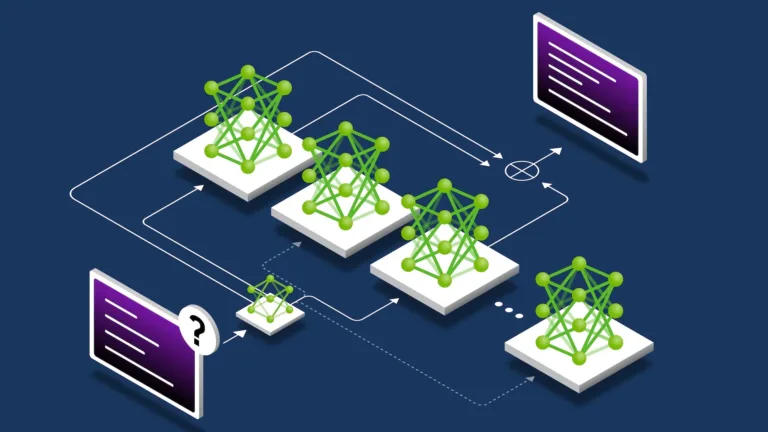
The exponential growth in large language model complexity has created challenges, such as models too large for single GPUs, workloads that demand high…
The exponential growth in large language model complexity has created challenges, such as models too large for single GPUs, workloads that demand high throughput and low latency, and infrastructure that must coordinate thousands of interconnected components seamlessly. The NVIDIA Run:ai v2.23 release addresses these challenges through an integration with NVIDIA Dynamo—a high-throughput…