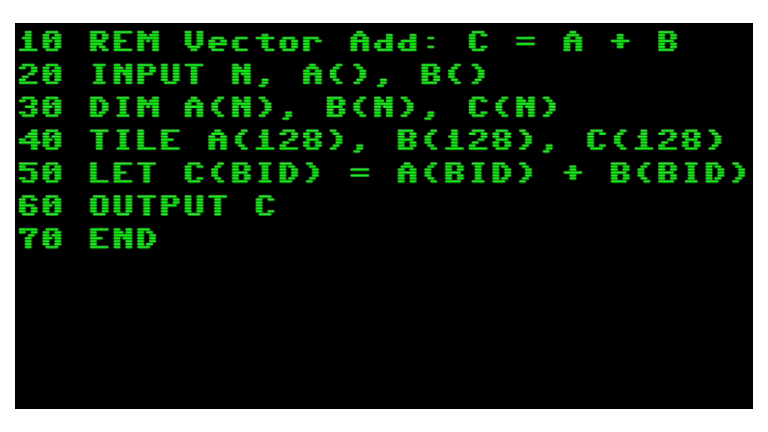
Large Language Models (LLMs) are at the forefront of AI innovation, but their massive size can complicate inference efficiency. Models such as Llama 3 70B and…
Large Language Models (LLMs) are at the forefront of AI innovation, but their massive size can complicate inference efficiency. Models such as Llama 3 70B and Llama 4 Scout 109B may require more memory than is included in the GPU, especially when including large context windows. For example, loading Llama 3 70B and Llama 4 Scout 109B models in half precision (FP16) requires approximately 140…