
Large language models and the applications they power enable unprecedented opportunities for organizations to get deeper insights from their data reservoirs and to build entirely new classes of applications.
But with opportunities often come challenges.
Both on premises and in the cloud, applications that are expected to run in real time place significant demands on data center infrastructure to simultaneously deliver high throughput and low latency with one platform investment.
To drive continuous performance improvements and improve the return on infrastructure investments, NVIDIA regularly optimizes the state-of-the-art community models, including Meta’s Llama, Google’s Gemma, Microsoft’s Phi and our own NVLM-D-72B, released just a few weeks ago.
Relentless Improvements
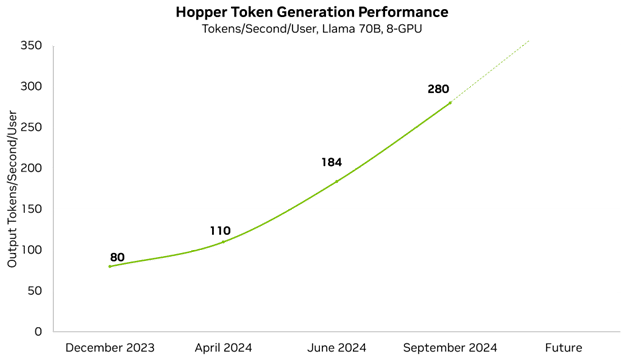
Performance improvements let our customers and partners serve more complex models and reduce the needed infrastructure to host them. NVIDIA optimizes performance at every layer of the technology stack, including TensorRT-LLM, a purpose-built library to deliver state-of-the-art performance on the latest LLMs. With improvements to the open-source Llama 70B model, which delivers very high accuracy, we’ve already improved minimum latency performance by 3.5x in less than a year.
We’re constantly improving our platform performance and regularly publish performance updates. Each week, improvements to NVIDIA software libraries are published, allowing customers to get more from the very same GPUs. For example, in just a few months’ time, we’ve improved our low-latency Llama 70B performance by 3.5x.
NVIDIA has increased performance on the Llama 70B model by 3.5x.
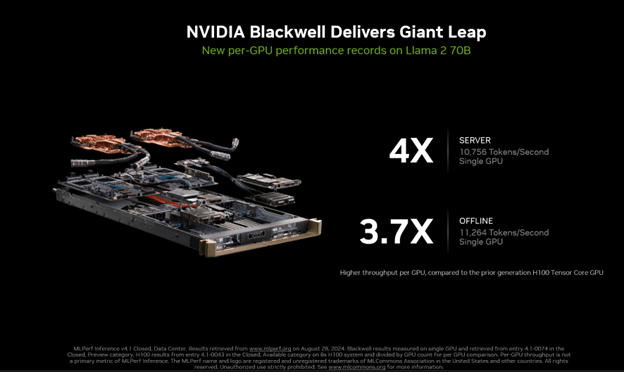
In the most recent round of MLPerf Inference 4.1, we made our first-ever submission with the Blackwell platform. It delivered 4x more performance than the previous generation.
This submission was also the first-ever MLPerf submission to use FP4 precision. Narrower precision formats, like FP4, reduces memory footprint and memory traffic, and also boost computational throughput. The process takes advantage of Blackwell’s second-generation Transformer Engine, and with advanced quantization techniques that are part of TensorRT Model Optimizer, the Blackwell submission met the strict accuracy targets of the MLPerf benchmark.
Blackwell B200 delivers up to 4x more performance versus previous generation on MLPerf Inference v4.1’s Llama 2 70B workload.
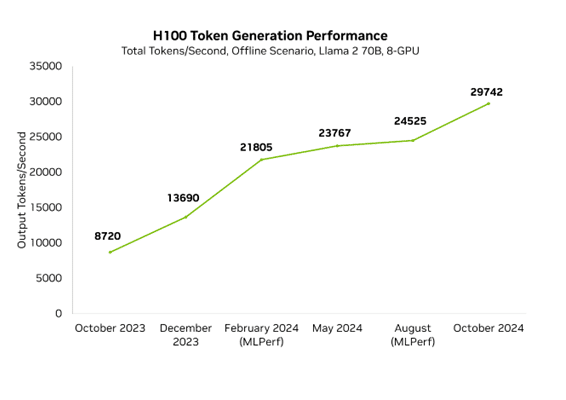
Improvements in Blackwell haven’t stopped the continued acceleration of Hopper. In the last year, Hopper performance has increased 3.4x in MLPerf on H100 thanks to regular software advancements. This means that NVIDIA’s peak performance today, on Blackwell, is 10x faster than it was just one year ago on Hopper.
These results track progress on the MLPerf Inference Llama 2 70B Offline scenario over the past year.
Our ongoing work is incorporated into TensorRT-LLM, a purpose-built library to accelerate LLMs that contain state-of-the-art optimizations to perform inference efficiently on NVIDIA GPUs. TensorRT-LLM is built on top of the TensorRT Deep Learning Inference library and leverages much of TensorRT’s deep learning optimizations with additional LLM-specific improvements.
Improving Llama in Leaps and Bounds
More recently, we’ve continued optimizing variants of Meta’s Llama models, including versions 3.1 and 3.2 as well as model sizes 70B and the biggest model, 405B. These optimizations include custom quantization recipes, as well as efficient use of parallelization techniques to more efficiently split the model across multiple GPUs, leveraging NVIDIA NVLink and NVSwitch interconnect technologies. Cutting-edge LLMs like Llama 3.1 405B are very demanding and require the combined performance of multiple state-of-the-art GPUs for fast responses.
Parallelism techniques require a hardware platform with a robust GPU-to-GPU interconnect fabric to get maximum performance and avoid communication bottlenecks. Each NVIDIA H200 Tensor Core GPU features fourth-generation NVLink, which provides a whopping 900GB/s of GPU-to-GPU bandwidth. Every eight-GPU HGX H200 platform also ships with four NVLink Switches, enabling every H200 GPU to communicate with any other H200 GPU at 900GB/s, simultaneously.
Many LLM deployments use parallelism over choosing to keep the workload on a single GPU, which can have compute bottlenecks. LLMs seek to balance low latency and high throughput, with the optimal parallelization technique depending on application requirements.
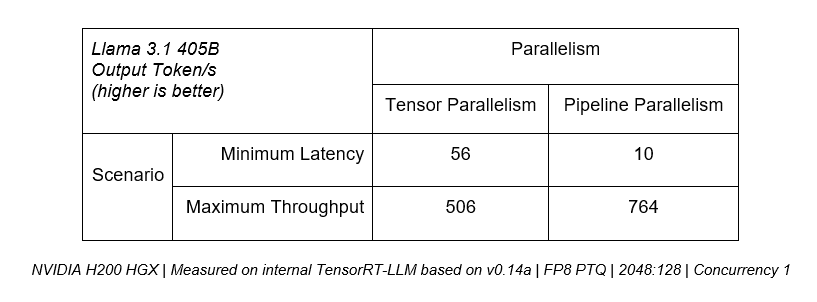
For instance, if lowest latency is the priority, tensor parallelism is critical, as the combined compute performance of multiple GPUs can be used to serve tokens to users more quickly. However, for use cases where peak throughput across all users is prioritized, pipeline parallelism can efficiently boost overall server throughput.
The table below shows that tensor parallelism can deliver over 5x more throughput in minimum latency scenarios, whereas pipeline parallelism brings 50% more performance for maximum throughput use cases.
For production deployments that seek to maximize throughput within a given latency budget, a platform needs to provide the ability to effectively combine both techniques like in TensorRT-LLM.
Read the technical blog on boosting Llama 3.1 405B throughput to learn more about these techniques.
Different scenarios have different requirements, and parallelism techniques bring optimal performance for each of these scenarios.
The Virtuous Cycle
Over the lifecycle of our architectures, we deliver significant performance gains from ongoing software tuning and optimization. These improvements translate into additional value for customers who train and deploy on our platforms. They’re able to create more capable models and applications and deploy their existing models using less infrastructure, enhancing their ROI.
As new LLMs and other generative AI models continue to come to market, NVIDIA will continue to run them optimally on its platforms and make them easier to deploy with technologies like NIM microservices and NIM Agent Blueprints.
Learn more with these resources:
Supercharging Llama 3.1 Across NVIDIA Platforms
NVIDIA NVLink and NVIDIA NVSwitch and Large Language Model Inference
Boosting Llama 3.1 405B up to 1.44x With NVIDIA TensorRT Model Optimizer
Low Latency Inference Chapter 1: Up to 1.9x Higher Llama 3.1 Performance
Blackwell Is Coming. NVIDIA GH200 NVL32 Gives Signs of Big Leap in Time to First Token Performance
Boosting Llama 3.1 405B Throughput by 1.5x on H200 Tensor Core GPUs











{kind=link}
{kind=link}
{kind=link}
{kind=link}