
Editor’s note: This post is part of the AI Decoded series, which demystifies AI by making the technology more accessible, and which showcases new hardware, software, tools and accelerations for RTX PC users.
Skyscrapers start with strong foundations. The same goes for apps powered by AI.
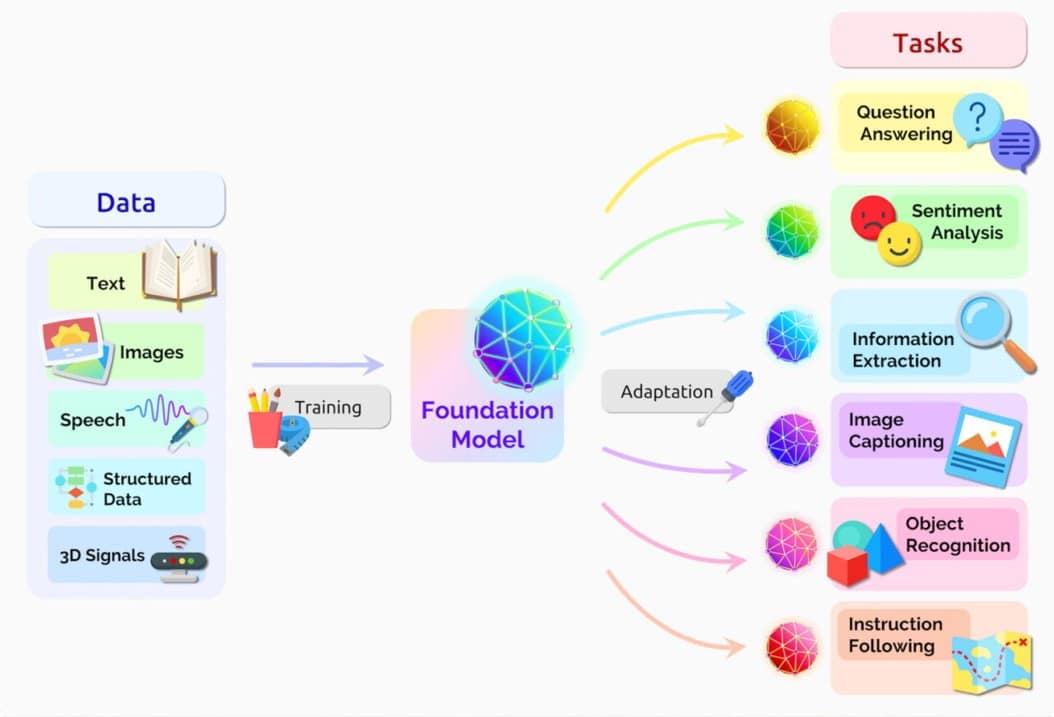
A foundation model is an AI neural network trained on immense amounts of raw data, generally with unsupervised learning.
It’s a type of artificial intelligence model trained to understand and generate human-like language. Imagine giving a computer a huge library of books to read and learn from, so it can understand the context and meaning behind words and sentences, just like a human does.
A foundation model’s deep knowledge base and ability to communicate in natural language make it useful for a broad range of applications, including text generation and summarization, copilot production and computer code analysis, image and video creation, and audio transcription and speech synthesis.
ChatGPT, one of the most notable generative AI applications, is a chatbot built with OpenAI’s GPT foundation model. Now in its fourth version, GPT-4 is a large multimodal model that can ingest text or images and generate text or image responses.
Online apps built on foundation models typically access the models from a data center. But many of these models, and the applications they power, can now run locally on PCs and workstations with NVIDIA GeForce and NVIDIA RTX GPUs.
Foundation Model Uses
Foundation models can perform a variety of functions, including:
Language processing: understanding and generating text
Code generation: analyzing and debugging computer code in many programming languages
Visual processing: analyzing and generating images
Speech: generating text to speech and transcribing speech to text
They can be used as is or with further refinement. Rather than training an entirely new AI model for each generative AI application — a costly and time-consuming endeavor — users commonly fine-tune foundation models for specialized use cases.
Pretrained foundation models are remarkably capable, thanks to prompts and data-retrieval techniques like retrieval-augmented generation, or RAG. Foundation models also excel at transfer learning, which means they can be trained to perform a second task related to their original purpose.
For example, a general-purpose large language model (LLM) designed to converse with humans can be further trained to act as a customer service chatbot capable of answering inquiries using a corporate knowledge base.
Enterprises across industries are fine-tuning foundation models to get the best performance from their AI applications.
Types of Foundation Models
More than 100 foundation models are in use — a number that continues to grow. LLMs and image generators are the two most popular types of foundation models. And many of them are free for anyone to try — on any hardware — in the NVIDIA API Catalog.
LLMs are models that understand natural language and can respond to queries. Google’s Gemma is one example; it excels at text comprehension, transformation and code generation. When asked about the astronomer Cornelius Gemma, it shared that his “contributions to celestial navigation and astronomy significantly impacted scientific progress.” It also provided information on his key achievements, legacy and other facts.
Extending the collaboration of the Gemma models, accelerated with the NVIDIA TensorRT-LLM on RTX GPUs, Google’s CodeGemma brings powerful yet lightweight coding capabilities to the community. CodeGemma models are available as 7B and 2B pretrained variants that specialize in code completion and code generation tasks.
MistralAI’s Mistral LLM can follow instructions, complete requests and generate creative text. In fact, it helped brainstorm the headline for this blog, including the requirement that it use a variation of the series’ name “AI Decoded,” and it assisted in writing the definition of a foundation model.
Meta’s Llama 2 is a cutting-edge LLM that generates text and code in response to prompts.
Mistral and Llama 2 are available in the NVIDIA ChatRTX tech demo, running on RTX PCs and workstations. ChatRTX lets users personalize these foundation models by connecting them to personal content — such as documents, doctors’ notes and other data — through RAG. It’s accelerated by TensorRT-LLM for quick, contextually relevant answers. And because it runs locally, results are fast and secure.
Image generators like StabilityAI’s Stable Diffusion XL and SDXL Turbo let users generate images and stunning, realistic visuals. StabilityAI’s video generator, Stable Video Diffusion, uses a generative diffusion model to synthesize video sequences with a single image as a conditioning frame.
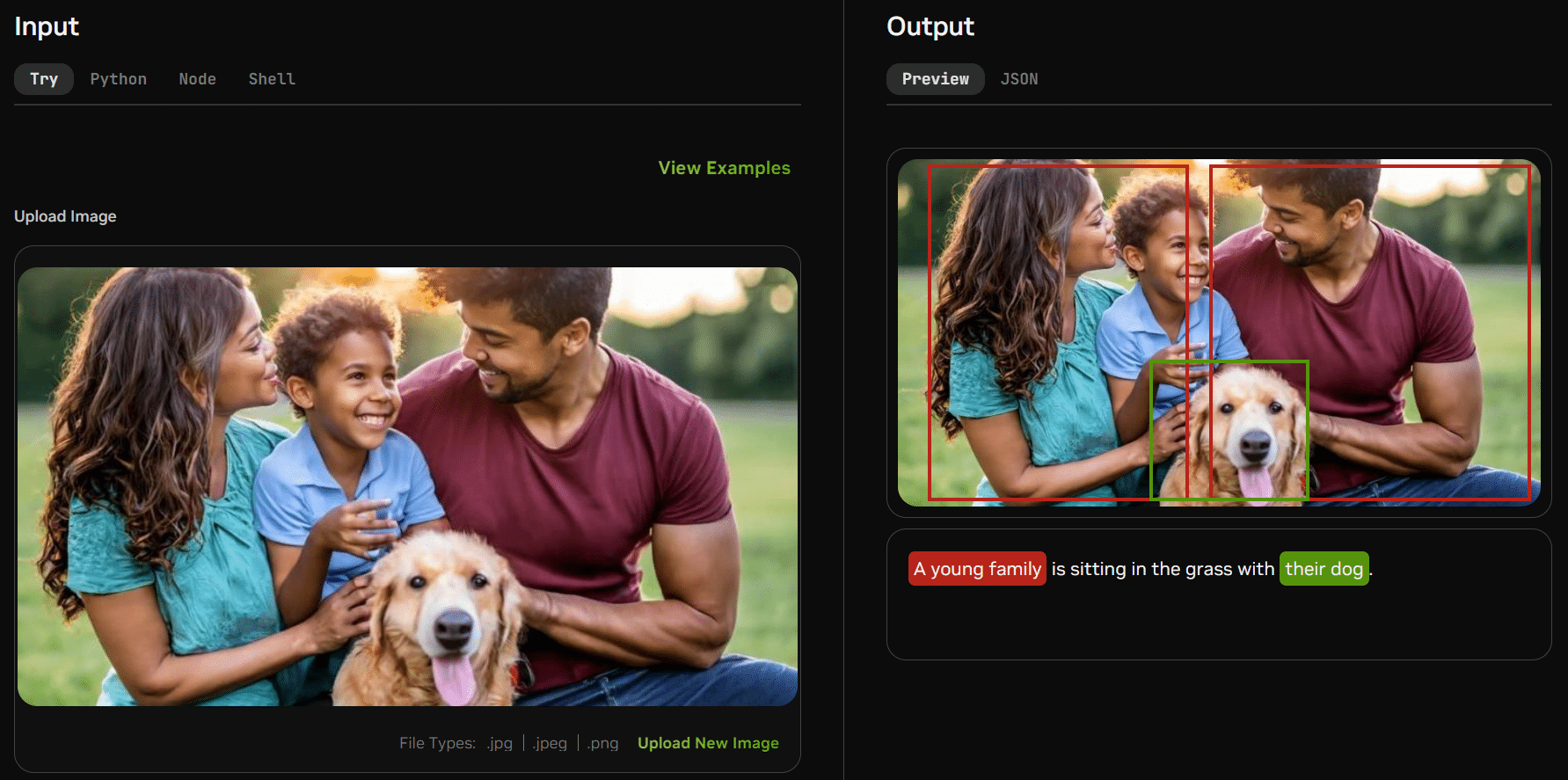
Multimodal foundation models can simultaneously process more than one type of data — such as text and images — to generate more sophisticated outputs.
A multimodal model that works with both text and images could let users upload an image and ask questions about it. These types of models are quickly working their way into real-world applications like customer service, where they can serve as faster, more user-friendly versions of traditional manuals.
Many foundation models are free to try — on any hardware — in the NVIDIA API Catalog.
Kosmos 2 is Microsoft’s groundbreaking multimodal model designed to understand and reason about visual elements in images.
Think Globally, Run AI Models Locally
GeForce RTX and NVIDIA RTX GPUs can run foundation models locally.
The results are fast and secure. Rather than relying on cloud-based services, users can harness apps like ChatRTX to process sensitive data on their local PC without sharing the data with a third party or needing an internet connection.
Users can choose from a rapidly growing catalog of open foundation models to download and run on their own hardware. This lowers costs compared with using cloud-based apps and APIs, and it eliminates latency and network connectivity issues. Generative AI is transforming gaming, videoconferencing and interactive experiences of all kinds. Make sense of what’s new and what’s next by subscribing to the AI Decoded newsletter.












{kind=link}
{kind=link}
{kind=link}